
The Multi-Agent Redesign Behind Matrix
For over two years now, Hebbia has been using large language models (LLMs) to automate information retrieval workflows. At the core of our product offerings is the Hebbia Matrix: a spreadsheet-like interface that allows our customers to run LLMs at scale over a near-unlimited corpus of documents.
Using an LLM-powered copilot known as the Matrix Agent, a Hebbia customer can then directly ask questions over the Matrix, extract information or pull in additional sources.
As the quality, capability, and availability of LLMs in Hebbia’s platform improved, customers began applying Matrix to larger and more ambitious tasks. Today, it is common to see thousands of rows and dozens of columns of LLM-generated content in a single grid.
Faced with an increasing volume of data and tasked with ever-more-complex analysis, our existing Matrix Agent implementation was pushed to its limits. At the end of last year, we returned to the drawing board and redesigned Matrix Agent, culminating in the development of a “multi-agent” framework scalable to problems of arbitrary complexity.
In the following blog, we'll examine Hebbia's multi-agent redesign, including a technical overview of what has changed.
From Matrix Agent 1.0 to Matrix Agent 2.0
Matrix Agent was designed as a copilot for Matrix, with the following core capabilities:
- Document Retrieval - Pulling in additional information sources as needed.
- Column Generation - Decomposing user requests into discrete information fields and extracting these by adding columns to the Matrix.
- Information Synthesis - Extracting information from the Matrix and producing well-formatted outputs.
Importantly, a given user request might require an arbitrary combination of the tasks above. For instance, a request such as “Which of the big tech giants is most profitable?” might require:
- Fetching latest financial filings for Alphabet, Amazon, Apple, Meta and Microsoft.
- Adding one or more columns on the Matrix to extract the profit for each company.
- Synthesizing the outputs from 1) and 2) into a cohesive prose response.
To perform these tasks, Matrix Agent 1.0 had access to a number of tools. We define “tools” and “agents” as follows:
- Tool - A function that performs a pre-defined action, e.g. adding documents to the Matrix.
- Agent - An LLM capable of making decisions, such as invoking tools, in response to a given environment.
Matrix Agent 1.0 and all its tools are illustrated in the flowchart below.
Matrix Agent 1.0 Diagram
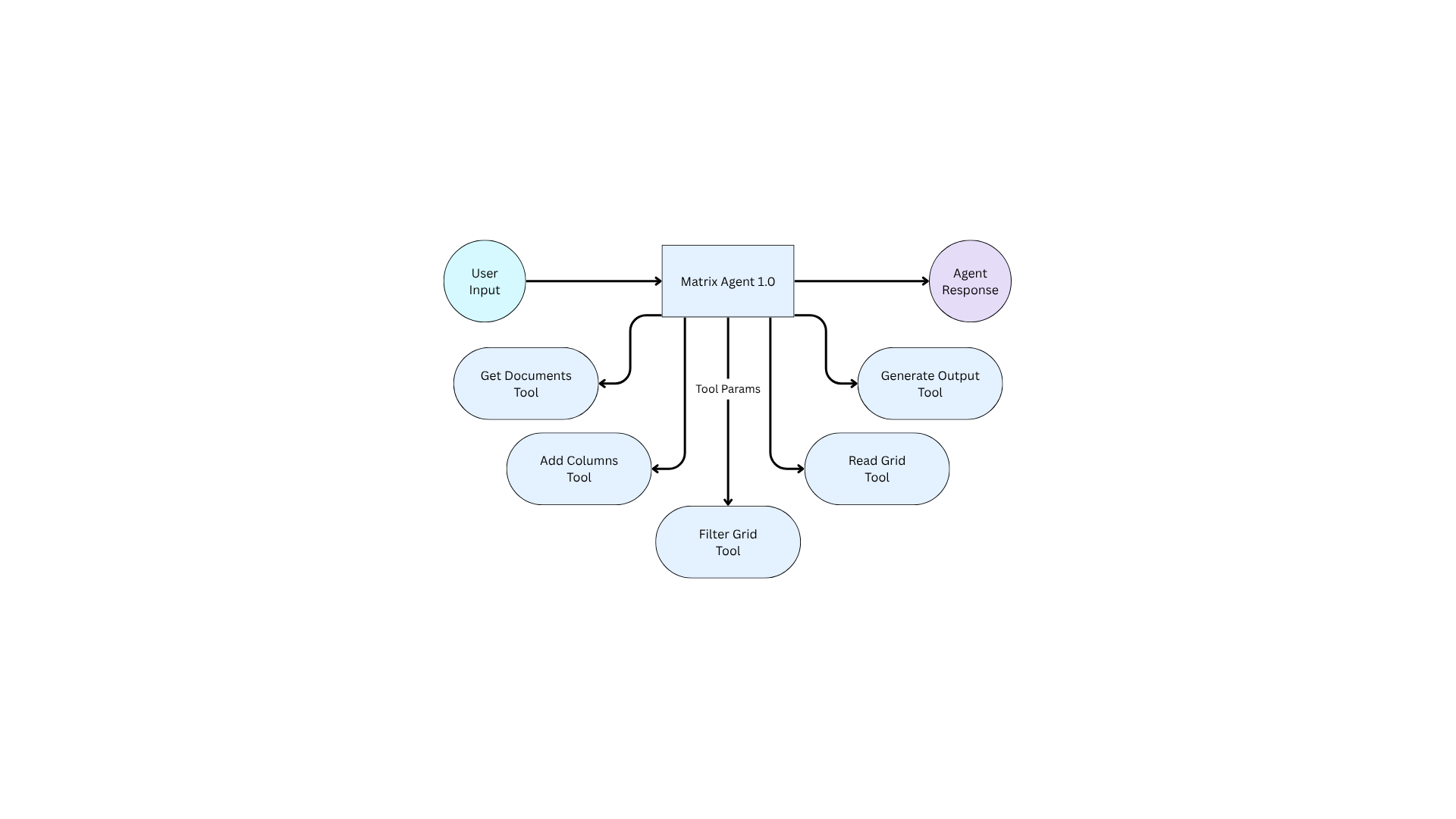
Matrix Agent 1.0 invoked tools sequentially in a loop, until satisfied with its response. However, as the size of the Matrix and the complexity of user inputs grew, several challenges became apparent:
- Overloaded Tooling: Agent 1.0 bundled every tool into a single agent. This approach often resulted in misinterpretations of instructions and confusion over which tool should be executed for a given task.
- Needle in the Haystack Problems: The content of the Matrix and the output from all tool calls often filled the LLM context window, resulting in higher latency and recall problems. The information relevant to any individual user query was a small component of the large amount of text provided to the LLM.
- Complex Chat Histories: Our initial agent design used an unstructured data store for chat messages to maximize flexibility and development speed. Query patterns became convoluted and had performance issues, further hurting latency and traceability.
- Complicated Internal Prompting: Instructions for all different tasks and scenarios had to be stuffed into a single system prompt. This one-size-fits-all prompting approach struggled to differentiate contexts and deliver the right instructions to the appropriate internal tool.
These issues spurred us to reimagine and rebuild the system, harnessing lessons learned to forge a more scalable, accurate, and maintainable solution.
Where Existing Agentic Frameworks Fall Short
Before diving into what makes Agent 2.0 special, it’s crucial to understand why writing our own framework was necessary. Our deep dive into the available open-source frameworks in November 2024 revealed several key limitations:
- Unproven Frameworks: Many contemporary solutions were still in early alpha stages or were merely demonstrative products without commitment to production-level reliability. Their focus was often on observability or flashy demos rather than robust core functionality.
- Context Management Shortcomings: No existing framework adequately addressed the management of highly specific contexts. With multiple applications at Hebbia posed to use this framework—each with its own nuanced context requirements—the need for strongly typed, hierarchical context classes became critical.
- Volume at Scale: Our operations demand handling enormous volumes of data with low latency. Hebbia’s own Maximizer service was already tackling high-scale LLM request scheduling, and we needed the agent framework to seamlessly integrate with this ecosystem. For a detailed look at the scalability challenge and our solutions, see this blog post on Hebbia Maximizer.
This is why we needed to develop our own framework to upgrade Hebbia Agent.
The Hebbia Agent 2.0 Solution
Orchestration & the Subagent Framework
At the heart of Agent 2.0 is a reimagined orchestration model that divides responsibilities between a central orchestrator and multiple specialized subagents. Think of it like a synchronized yoyo: the user’s request is first received by the orchestrator, which then dispatches sub-agents tailored to specific tasks.
These sub-agents focus on individual job segments—be it context extraction, information retrieval, or output formatting—and then report back to the orchestrator to decide on the next step, finally deciding to call an output agent to compile a synthesized final response.
You can see a full flowchart diagram of Hebbia Agent 2.0 below
Hebbia Agent 2.0 Diagram
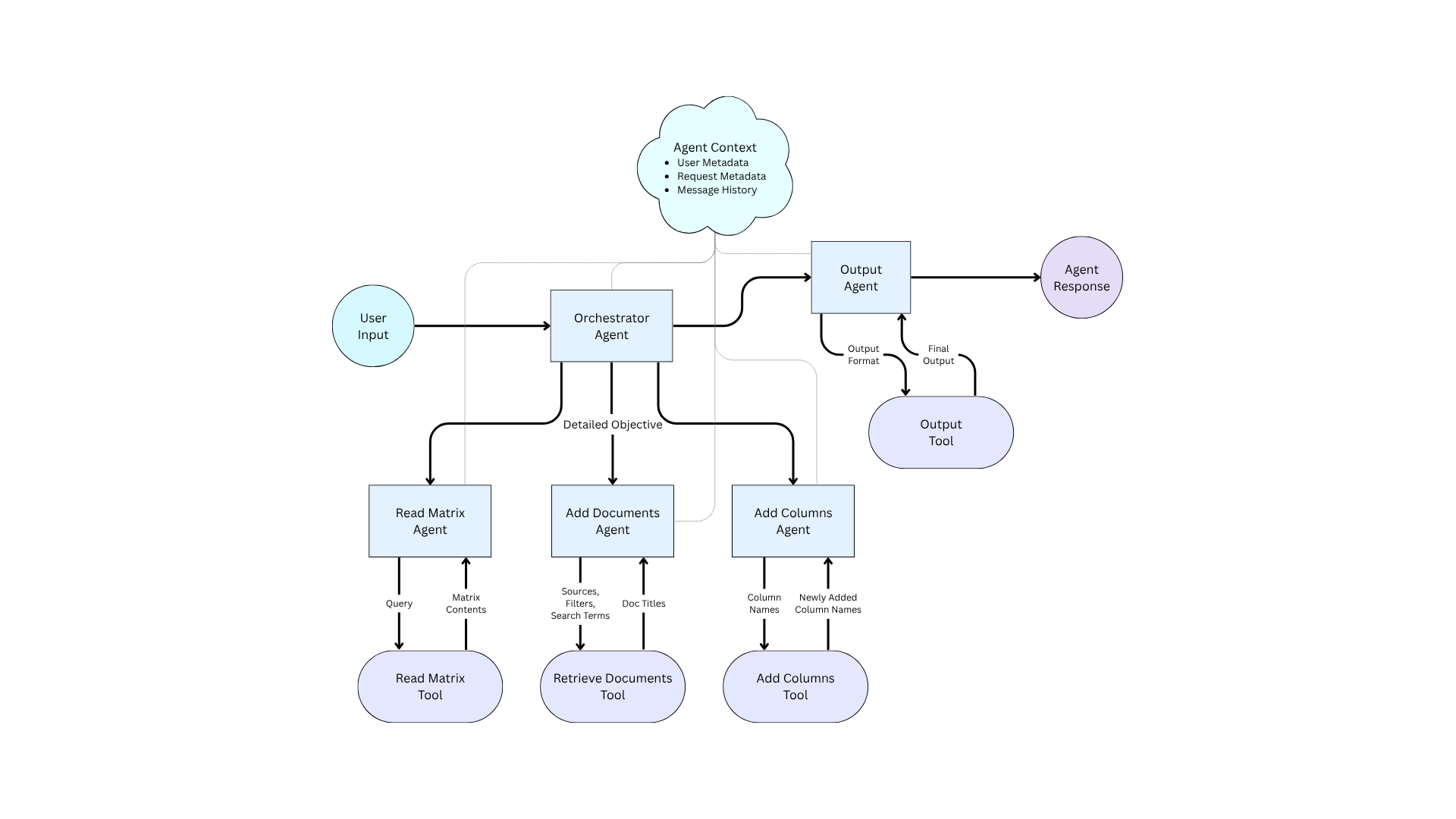
Crucially, the orchestrator never directly invokes any tools: it simply passes a text-based “detailed objective” to a chosen subagent, like a manager delegating tasks to employees. The orchestrator is therefore only provided the subagent’s name and a description of its capabilities. It is not aware of or responsible for the tools used internally by each subagent.
For example, below we illustrate a case where the “Orchestrator”, tasked with analyzing a Matrix, invokes the “Read Matrix” subagent.
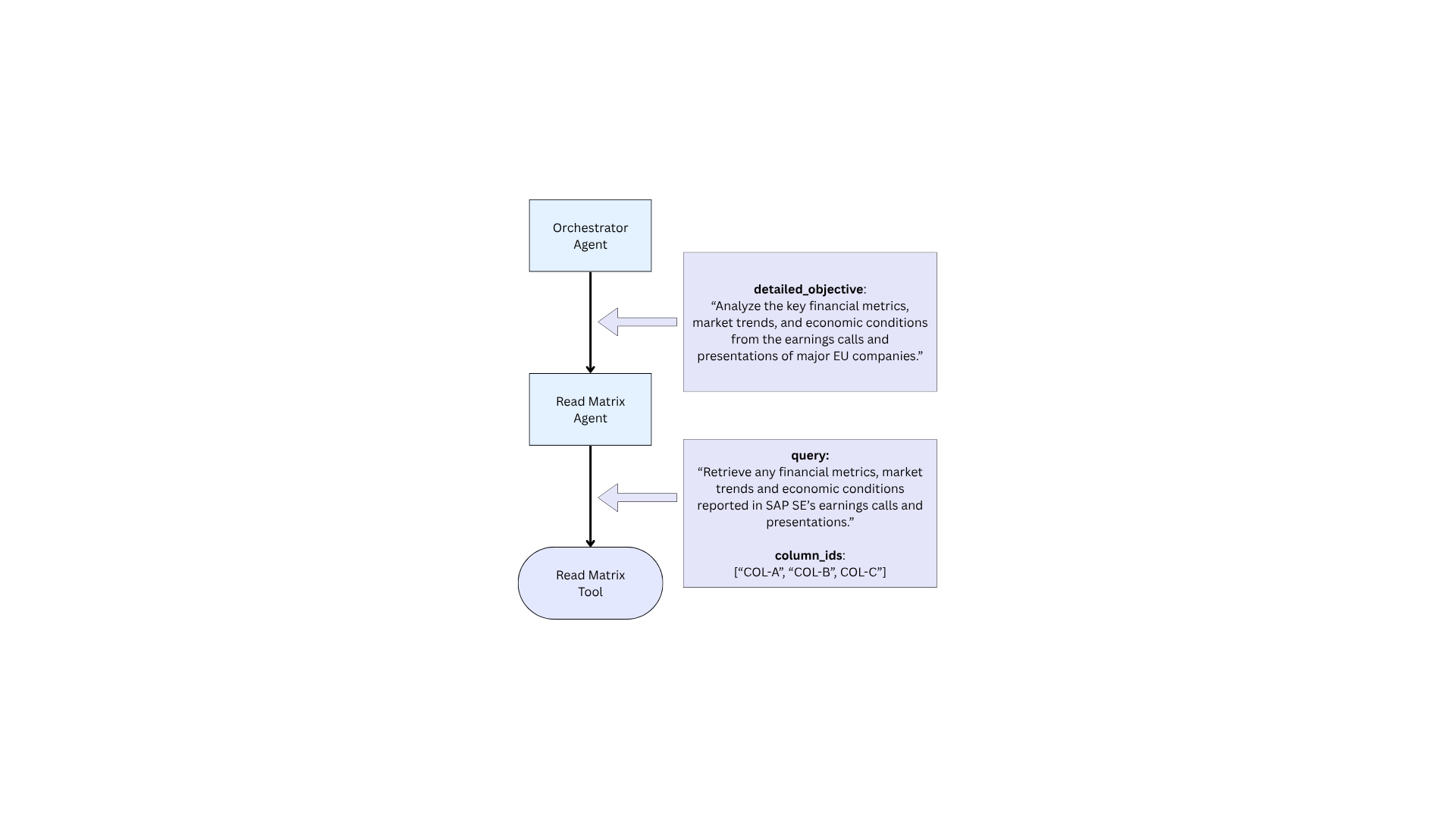
The “Read Matrix” subagent is entirely responsible for selecting columns to read from the Matrix via the read matrix tool, saving the orchestrator from having to be aware of the available columns and rows in the matrix entirely.
Context as a Core Concept
A central upgrade in Hebbia Agent 2.0 is the structured handling of context. At a baseline level, the context contains only the following properties:
- Message History (Including Agent Source): We tag each message in message_history with the agent that produced it, to let subagents filter for the relevant messages to do their jobs. For example, the orchestrator doesn’t care which columns were read when deciding on what steps to take next, but the output agent may want this information when reporting back to the user how information was generated
- Observability and Data Security: We use Datadog logging and tracing extensively for observability, ensuring our systems are monitored effectively. Each client input is identified by a turn_id, representing all the actions taken during an entire Agent lifecycle. Multiple turn_ids may correspond to a single session_id as a user sends follow-up messages. UUID1 is chosen here for easy sorting.
- Asynchronous Processing with Python: We use Python’s asyncio queues to manage long-running processes and loading states in a non-blocking manner. This ensures the system feels responsive to the user when processing complicated tasks.
- Protocol Agnosticism: Our framework supports both server-sent events and websockets without compromising performance. This flexibility allows us to apply the framework to a variety of different products, including our Chat app.
- Strongly Typed Hierarchical Contexts: By rigorously defining and separating context classes, we effectively avoid the pitfalls of overloading a single context class with unneeded information. This specificity reduces complexity, forcing developers to consider if they can reuse an existing context rather than adding yet another field to the context.
These new properties allow Hebbia Agent 2.0 to greatly expand its technical capacities.
Results: Enhanced Capability, Reliability, and Extensibility
The shift to Agent 2.0 has led to several measurable improvements:
- Extensibility: We have the same framework powering two different products already in production: Matrix Agent and Chat. We are currently building another agentic product that takes advantage of this framework too.
- Capability & Scale: The separation of information retrieval (handled by a dedicated ReadAgent) from output formatting (managed by an OutputAgent) has boosted overall quality. This layered approach ensures that even intricate user formatting requirements are met with precision.
- Reliability Improvements: One of the standout benefits is the near elimination of “tool use hallucinations”—a frequent issue in Agent 1.0, where tools were often mixed up or invoked with incorrect parameters. By isolating concerns, each subagent can be rigorously tested in isolation, enhancing observability and stability.
- Accelerated Development Velocity: The reuse of core agentic logic and shared constructs across teams has substantially reduced the time required to spin up new products. Moreover, the improved onboarding process has empowered teams to hit the ground running with minimal ramp-up time.
This combination of improvements has improved ROI for our customers.
Looking Ahead
Hebbia Agent 2.0 is not just an endpoint — it’s a foundation upon which future agentic products will be built.
As our framework continues to evolve, we’re excited by the prospect of even more sophisticated context-aware functionalities, distributing systems to run agents at an even greater scale, and ever-improving quality in our outputs.
If work like this is interesting to you - reach out! We’re always hiring and would love to have you join the team!


