
Introducing Hebbia's Financial AI Benchmark
As LLM innovation accelerates, finance professionals require a multi-model approach to uncover alpha. However, identifying the optimal model for specific needs remains a significant challenge. At Hebbia, we have spent years deeply understanding our customers’ diverse workflows—both typical and edge cases—and applying AI in ways that are both effective and realistic. Choosing the right LLM is central to this process.
We built the Financial Services Benchmark to identify the best models for workflows relevant to our customers in investment banking, private equity, credit, and public equities. Because our customers are highly discerning when it comes to numbers (they are, after all, in finance), we’ve made our statistical methodology fully transparent to the public.
Here are the key takeaways from our inaugural evaluation:
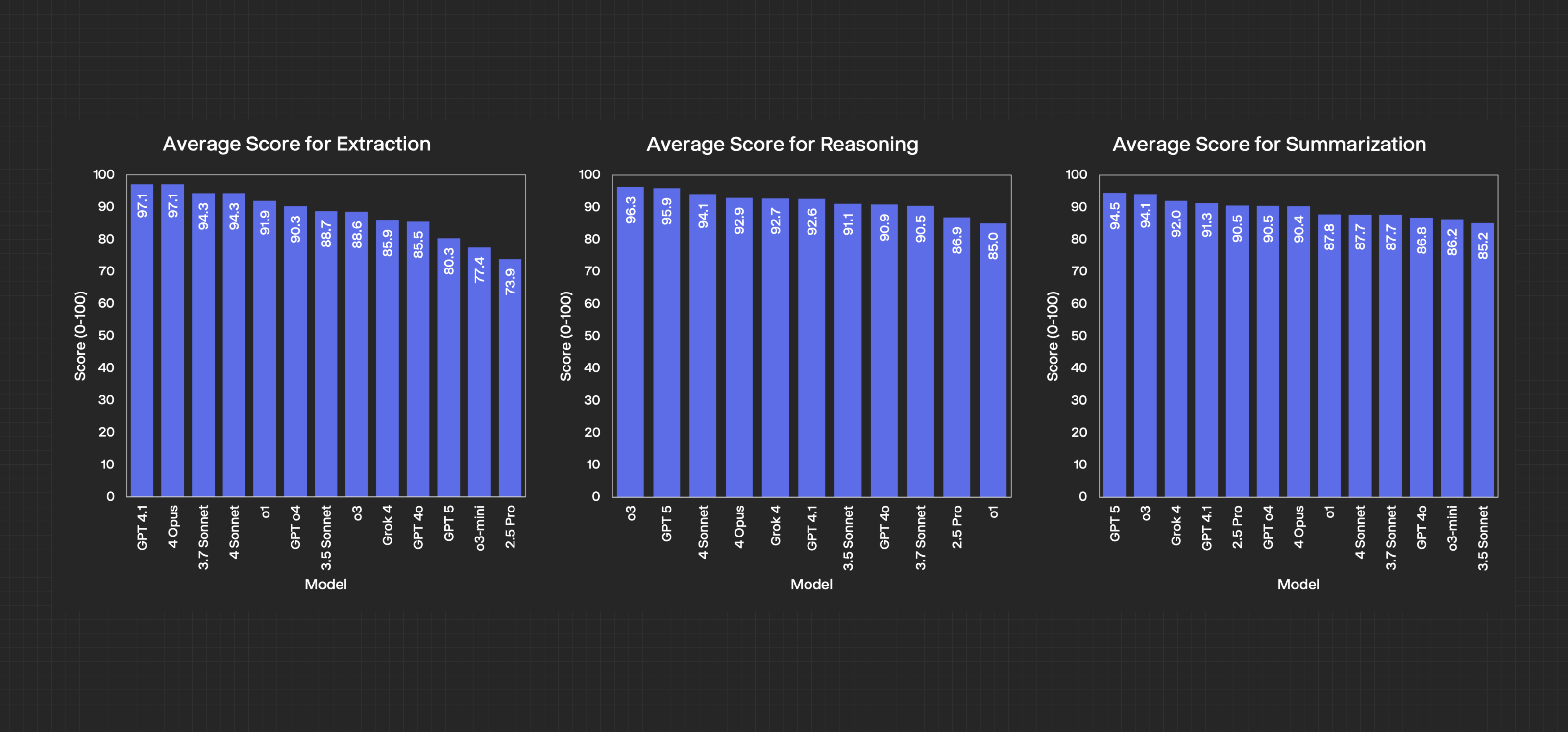
- For extraction tasks, such as pulling out exact numbers, terms, or quotes, Claude 4 Opus and GPT-4.1 performed best, accurately capturing specific details without errors or unnecessary information.
- For summarizing and reasoning, go with OpenAI’s o3 or GPT-5 models. o3 and GPT-5 consistently deliver the most insightful responses—surfacing deeper implications and strategic perspectives beyond restating facts. GPT-5 shot to the top of the leaderboard in summarization and reasoning, but its tendency to give overly detailed answers hurts precision on extractive tasks.
- With LLMs, you don't always get what you pay for. Our evaluation found that premium models often perform similarly to less expensive options. For many tasks, GPT-4.1 matched the performance of top-tier models at a fraction of the price.
The LLM landscape is evolving rapidly, with models becoming increasingly specialized. Anthropic’s Claude, for example, recently entered the top five for financial workflows in our evaluation, demonstrating how quickly rankings can shift. The best strategy to ensure you're always adopting a multi-model approach so your business can evolve as quickly as the models themselves.
No one-size fits all
We put leading models to the test, including OpenAI’s GPT 5, o3, and GPT-4.1, Anthropic’s Claude 4 series, Grok 4, and Google’s Gemini. Our results show that no single model excels at every task. Most models now handle basic accuracy and relevance well, but the real difference comes from how insightful and clear their answers are. Using a mix of models helps ensure you get the best results for each type of task.
Each model was evaluated on more than 600 real-world finance questions, organized into three main categories:
1. Extraction
These questions ask the model to find and report specific facts or details from documents. For example, “What was the company’s total revenue this quarter?”, “What were the promotions or limited time offerings this quarter” or “List all analyst questions asked by John Smith.” The goal is to measure how accurately the model can pull out exact numbers, terms, or quotes.
2. Summarization
In this category, the model is asked to condense information and highlight the main points. Prompts include, “Summarize management’s perspective on macroeconomic conditions,” or “Briefly describe the main factors affecting quarterly sales.” This tests the model’s ability to capture the essence of complex information.
3. Reasoning
These tasks require the model to analyze information and provide deeper insights. For example, “What were analysts most concerned about, and why is this important?” or “Identify and explain any questions management struggled to answer clearly.” Here, we look for the model’s ability to interpret, explain, and connect ideas.
GPT-4.1 and Claude 4 Opus are the most reliable for extraction, consistently pulling accurate details without unnecessary information. For summarization and reasoning, o3 and GPT 5 stands out by not just summarizing, but also explaining why the information matters and adding valuable context.
With LLMs, you don't always get what you pay for
Many finance teams gravitate toward the newest and most expensive language models, expecting them to deliver the best results. However, our benchmark shows that price and hype do not always translate to better performance. In practice, some premium models only slightly outperform, or even underperform, their predecessors on key finance tasks.
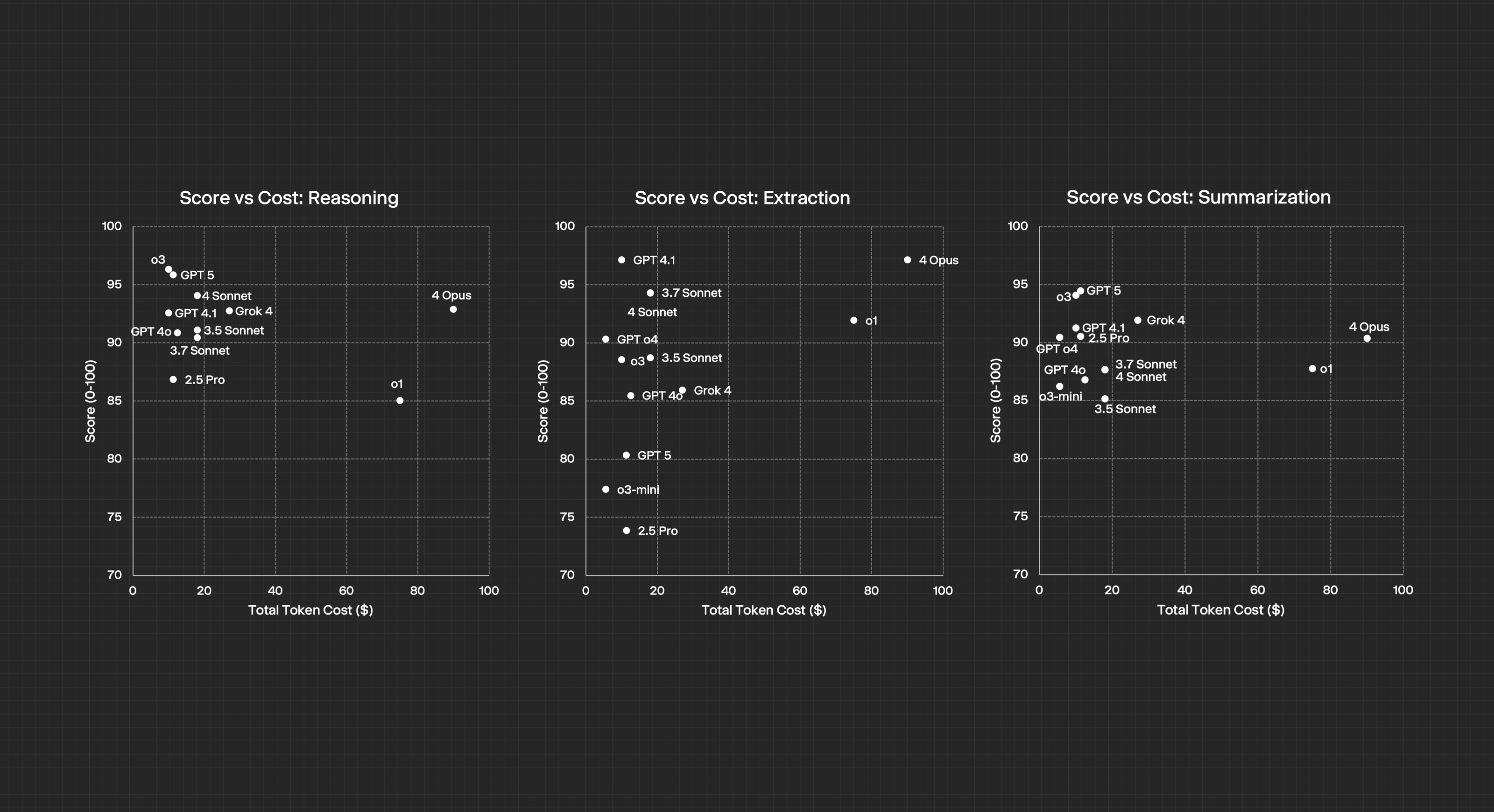
For example, Claude 4 models quickly entered our top five upon release, but further analysis shows their outputs are often similar to those of more affordable alternatives. Established models like GPT-4.1 continue to excel in critical extraction tasks that are essential for accurate financial analysis.
Even models that once led the field can quickly fall behind. OpenAI’s o1, previously the top reasoning model, is now surpassed by o3, which offers sharper insights at a better price. Teams still using o1 are paying more for outdated technology and missing out on improved performance.
Our evaluation makes it clear: the best approach is to match model selection directly to task performance. A well-tested, multi-model strategy ensures you get the best value and results for your organization.
Conclusion
The rapid evolution of LLMs presents both opportunity and complexity for financial services. Our evaluation makes it clear: there is no single “best” model for every workflow and price does not always correlate with performance. OpenAI’s o3 and GPT 5 excel at delivering insightful, strategic analysis, while GPT-4.1 and Claude 4 Opus lead in precise data extraction.
As the LLM landscape continues to shift, the smartest strategy is to remain agile and data-driven, leveraging a multi-model approach tailored to your organization’s unique needs. With the Financial Services Benchmark, finance teams can confidently select the right models for each task, maximize performance, and stay ahead in a rapidly changing market.
The future of AI in finance is about making informed, evidence-based choices that drive real value. With Hebbia, you’re equipped to do just that.


