
A Look Inside Hebbia's "Deeper" Research Agent
Discovering novel answers requires connecting a wide range of seemingly unrelated ideas. This is a challenge our customers tackle every day. OpenAI’s launch of Deep Research earlier this year transformed how people approach new domains, but as the technology spreads, it no longer gives our customers a competitive edge.
That’s why we created Deeper Research: a solution purpose-built for research-intensive industries like investing, banking, and law. It’s “deeper” because it introduces more steps in the research process and expands the range of data sources agents can search—including not just the web, but also private documents, PitchBook, S&P CapIQ, and more.
In this post, we’ll share how our research system works, how we’ve built around the limitations of MCP, and how we approach context engineering for high volumes of information. Ultimately, these innovations help make AI-powered research truly useful for the enterprise.
The Power of Multi-Agent Systems
While foundational LLMs offer impressive raw capabilities, it’s the collaboration of specialized agents that transforms these capabilities into enterprise-ready solutions. The future of intelligent systems for research tasks lies in architectures that can decompose complex goals, operate across diverse data sources, and dynamically adapt to new information.
Deeper Research is powered by a team of dozens of specialized agents. In any company, there’s usually a manager overseeing the work of several employees in different functions. The manager’s job is to make sure the employees are able to collaborate with each other to deliver results. Hebbia’s research agents operate the same way. Our system consists of the following agents:
- Orchestrator: Manage the research process, delegating tasks to each agent
- Planning: Decompose complex research goals into actionable steps
- Retrieval: Surface the most relevant data from public and private sources of data
- Document analysis: Extract insights from unstructured documents
- Distillation: Condense and structure information to fit within model context limits
- Reasoning: Dynamically assess and refine the research process
- Output: Synthesize findings and communicate with the user
Our multi-agent team approaches research as an explore-exploit tradeoff. First, the team explores the breadth of the research surface area by decomposing a user’s request into broad, actionable subtasks and familiarizing itself with the latest available information. The system then exploits areas of interest based on what it has learned, iteratively adapting and refining its focus as new insights emerge.
An agent can decompose an initial prompt into subtasks for other agents. Our framework is capable of spawning multiple subsystems of agents to tackle each subtask. This architecture gives our platform the flexibility to handle everything from straightforward questions to complex, multi-layered due diligence.
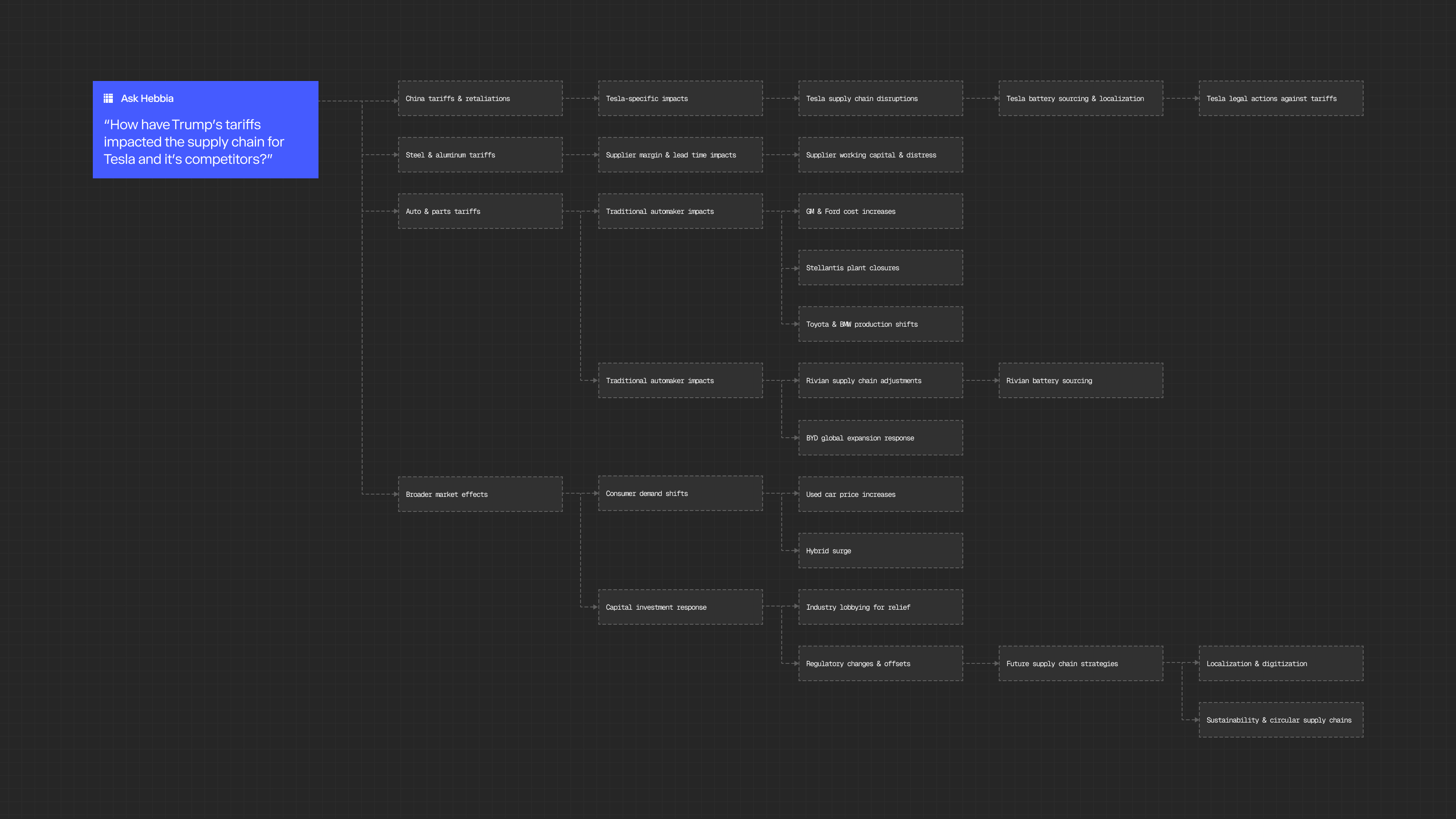
In a research system that meticulously examines every detail in a vast amount of information, ensuring transparency is crucial to maintain trust and accountability. Our agents communicate every step and provide claims that link directly to the original document quotation. This is achieved through Iterative Source Decomposition (ISD), which provides an audit trail to the precise source supporting the insight. Additionally, ISD can run on any LLM—OpenAI, Anthropic, Google—giving customers greater control over model selection to suit their specific needs.
While agent collaboration is central to our system’s intelligence, the effectiveness of these agents depends on their ability to retrieve and process information from a wide variety of sources. The next section examines how we address the complexities of real-world data retrieval.
Beyond MCP: Information Retrieval for Real-World Complexity
Our retrieval agents are designed to deliver higher accuracy, faster performance, and better coverage by tailoring their approach to the unique structure of each data source. They leverage bespoke data indexing, dynamic filtering, and multi-agent search strategies across the sources that matter most to our customers:
- Private Data: User’s private data uploaded or synced from file stores (e.g., SharePoint, Box)
- Public Company Data: SEC filings, earnings call transcripts, and investor presentations
- PitchBook: Structured firmographic profiles for millions of companies
- S&P Capital IQ Financial: Structured financial information from public and private companies
- Sector Insights: S&P market news and conference transcripts
- Web: Real-time access to information on the internet
The Model Context Protocol (MCP) is an open standard that enables large language models (LLMs) to access data from a variety of sources, representing a significant step toward data interoperability. However, the effectiveness of an MCP server depends on how each partner or data provider configures it, and since MCP is relatively new, not every implementation supports all possible workflows. As a result, retrieving data tailored to specific use cases may require additional customization. For example, answering complex questions—such as “What were the ten most recent M&A transactions in the chemicals sector over $10B?”—requires us to build custom indexing and search strategies to ensure reliable results. As the MCP ecosystem evolves, we remain committed to re-evaluating and adapting our approach to leverage future improvements.
With robust retrieval strategies in place, the challenge shifts to managing the vast amount of information surfaced by our agents. This brings us to the critical topic of context engineering in high-volume research environments.
Managing Context in High-Volume Research
One of the key technical challenges in scaling inference across a network of agents is managing context. A single prompt can use millions of tokens to process thousands of pages and coordinate analysis from dozens of agents. Managing this scale requires sophisticated context engineering to control what each agent sees, shares, and retains.
We address context management with a multi-pronged approach:
- Roles and responsibilities: Each agent has a clearly defined scope, ensuring only relevant history and information are included in its context.
- Inter-agent communication: Agents share only the information necessary for the next subtask, minimizing unnecessary context sharing.
- Context distillation: Information within the context window is compressed to its principal components, maximizing efficiency and relevance.
By defining precise roles and responsibilities, each agent operates within a well-bounded scope. For example, when an Orchestrator Agent needs to find revenue figures for two companies, it delegates each request to separate multi-agent subsystems. Each subsystem focuses on its specific assignment and operates independently. Agents return only their final results to the Orchestrator Agent, without sharing the details of how the information was found.
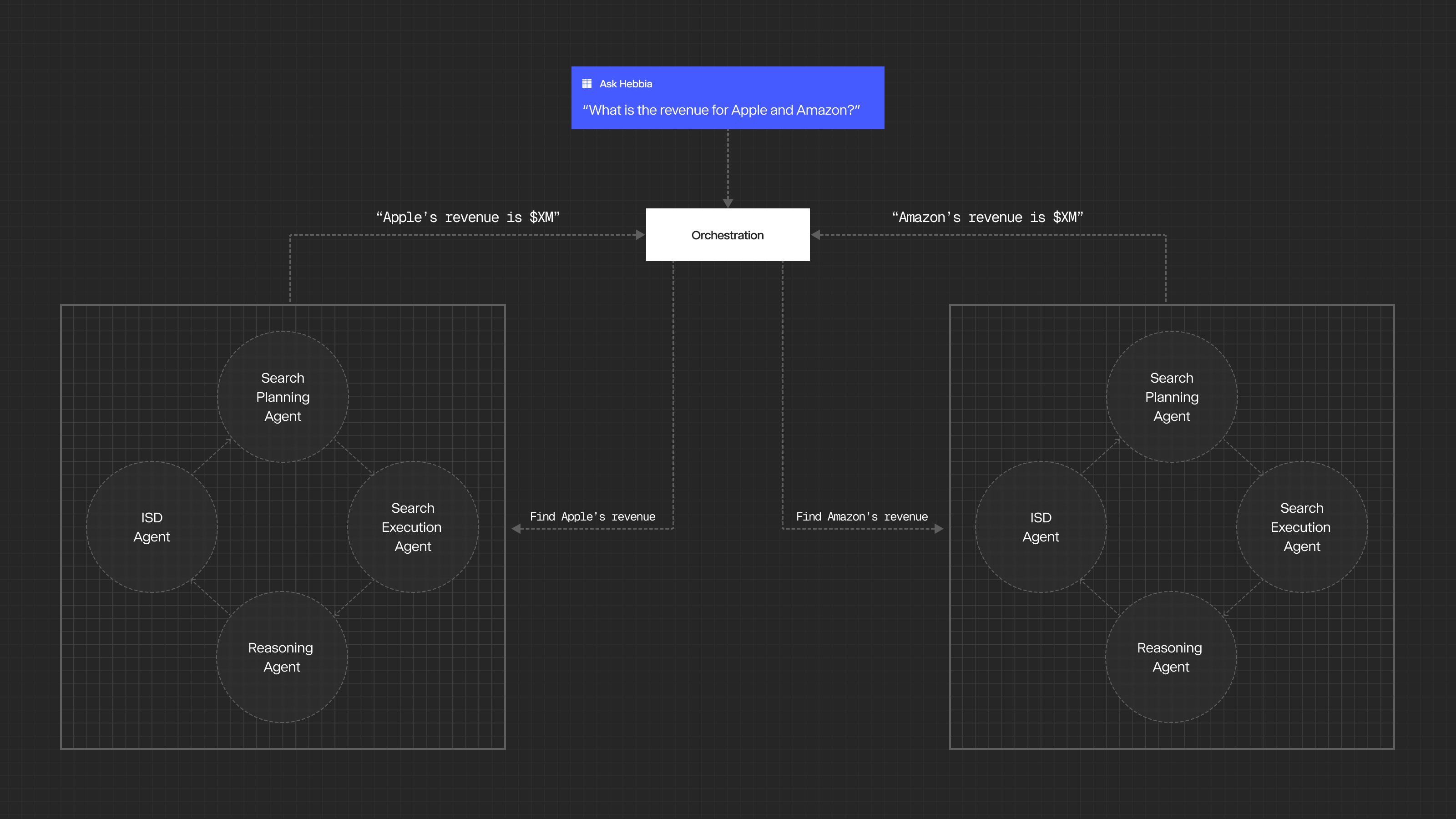
In many cases, agents only need a summary of the results from other agents rather than verbatim outputs. To support this, we developed a specialized Context Distillation Agent that reduces context to its principal components, allowing agents to leverage key insights and results. In our evaluation, the Context Distillation Agent reduces context size by over 90%, resulting in lower latency and higher recall. These targeted roles, selective communication, and context distillation techniques help reduce context size and enable agentic collaboration as the system scales to handle increasingly complex tasks.
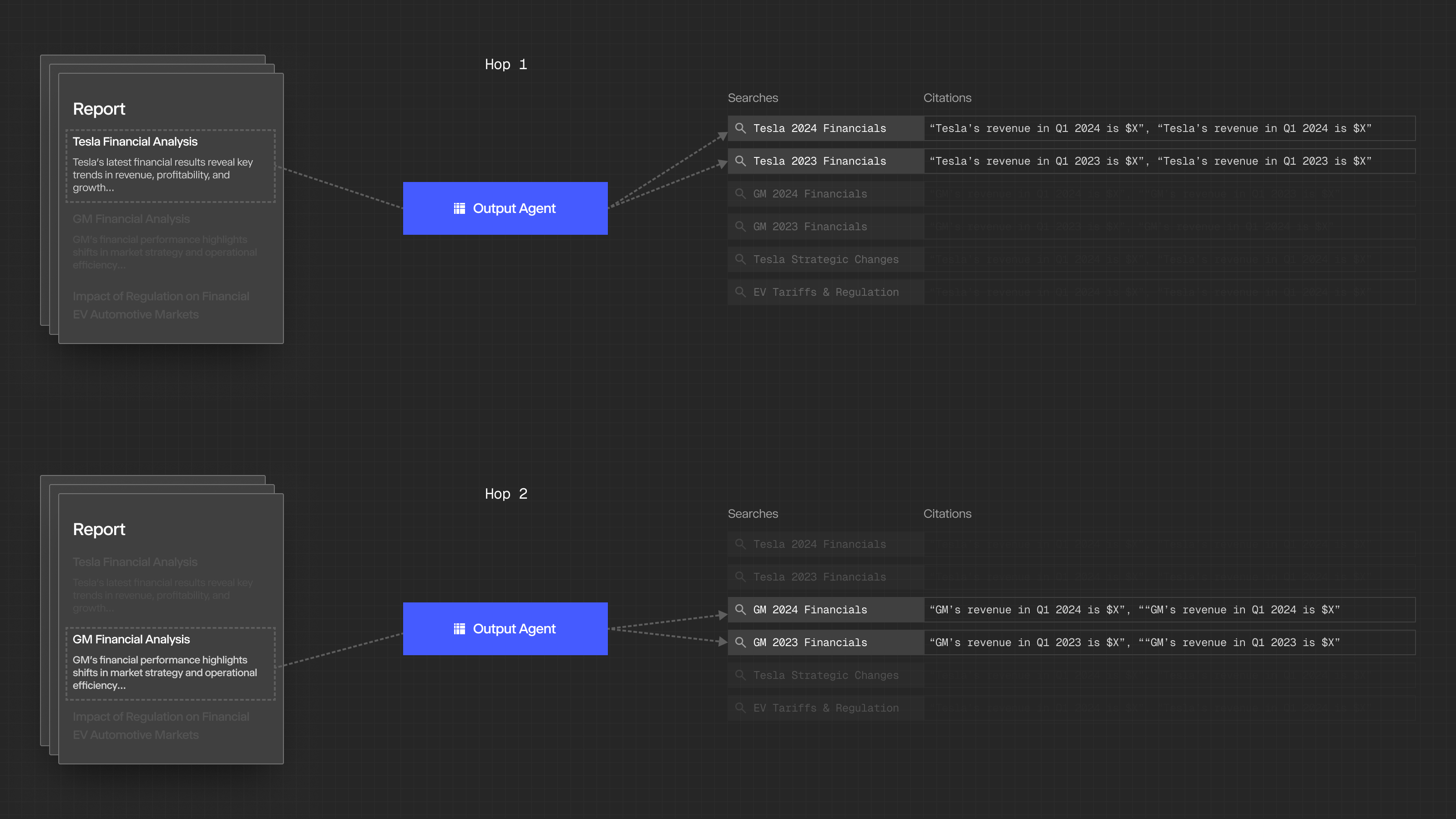
The greatest context engineering challenge lies with the Output Agent. This agent is responsible for writing a fully cited, exhaustive report using every relevant quotation gathered from the research process. Since the Output Agent can’t fit the entire body of research into its context window, it attends to relevant searches from the research. It writes the output section by section, using the output from previous sections as context for the current section. This “multi-hop” workflow enables our research process to generate comprehensive reports without ever exceeding its own context window.
While scaling inference across multiple agents unlocks new levels of intelligence, we are still constrained by the rate limits of our LLM providers. To meet these demands, every request is routed through Maximizer, our high-throughput LLM orchestration system that dynamically allocates token capacity across providers. Maximizer prioritizes our most important tasks, adapts to real-time availability, and keeps inference flowing with a throughput of billions of tokens per day.
What’s Next
Throughout this post, we’ve explored how Hebbia’s multi-agent system delivers accurate and actionable insights at an enterprise scale. By combining advanced context engineering, robust system orchestration, and a commitment to transparency and control, we aim to set a new standard for AI-powered research.
We are grateful for the trust and feedback from our customers, which continually shapes our development. As the landscape of enterprise research evolves, we remain dedicated to advancing our technology and empowering our customers to tackle even more ambitious challenges.
Thank you for joining us on this journey. We look forward to sharing future innovations and invite you to stay engaged as we continue to push the boundaries of what’s possible with agentic AI systems.
Author
William Luer
Lead Technical Staff
William Luer, Bowen Zhang
Engineering
Lucas Haarmann, Alex Flick, Jake Skinner, Sara Kemper, Tas Hasting, Adithya Ramanathan
+ with contributions from larger Hebbia technical staff


