
FFTxt: 30k Parameters Is All You Need
At Hebbia, diverse forms of content stream through our models from tens of thousands to millions of documents per minute. Many of these PDFs contain embedded images — scanned pages, diagrams, and photographs — essential for providing accurate answers with grounded citations. Delivering the best user experience means our routing and processing systems have to run in milliseconds with minimal memory overhead.
To extract the relevant content found within embedded images, Optical Character Recognition (OCR) is the standard choice. While today’s OCR models are powerful and accurate, they often rely on billions of parameters. Running these hefty multimodal models at scale incurs high latencies and even higher compute requirements. To support the scale of documents our platform processes, we needed a solution that selectively runs OCR on images that actually contain text. Many open-source models like resnet-152-text-detector could be fine-tuned to do the job, but at 58 million parameters, meeting our latency requirements would still demand GPU resources and the compute costs that come with them.
Our researchers at Hebbia have developed FFTxt as an elegant solution to maximize the efficiency, accuracy, and latency of our OCR pipeline. FFTxt leverages mathematical techniques from signal processing to detect images containing text in milliseconds on highly scalable and lightweight CPUs. The trick isn't architecture — it's clever feature engineering to achieve the efficiency we need.
The Problem with Pixel Analysis at Scale
A modest 512×512 grayscale image is 262,144 dimensions. Even with downsampling or learned compression, representations still scale with the image size O(W×H).
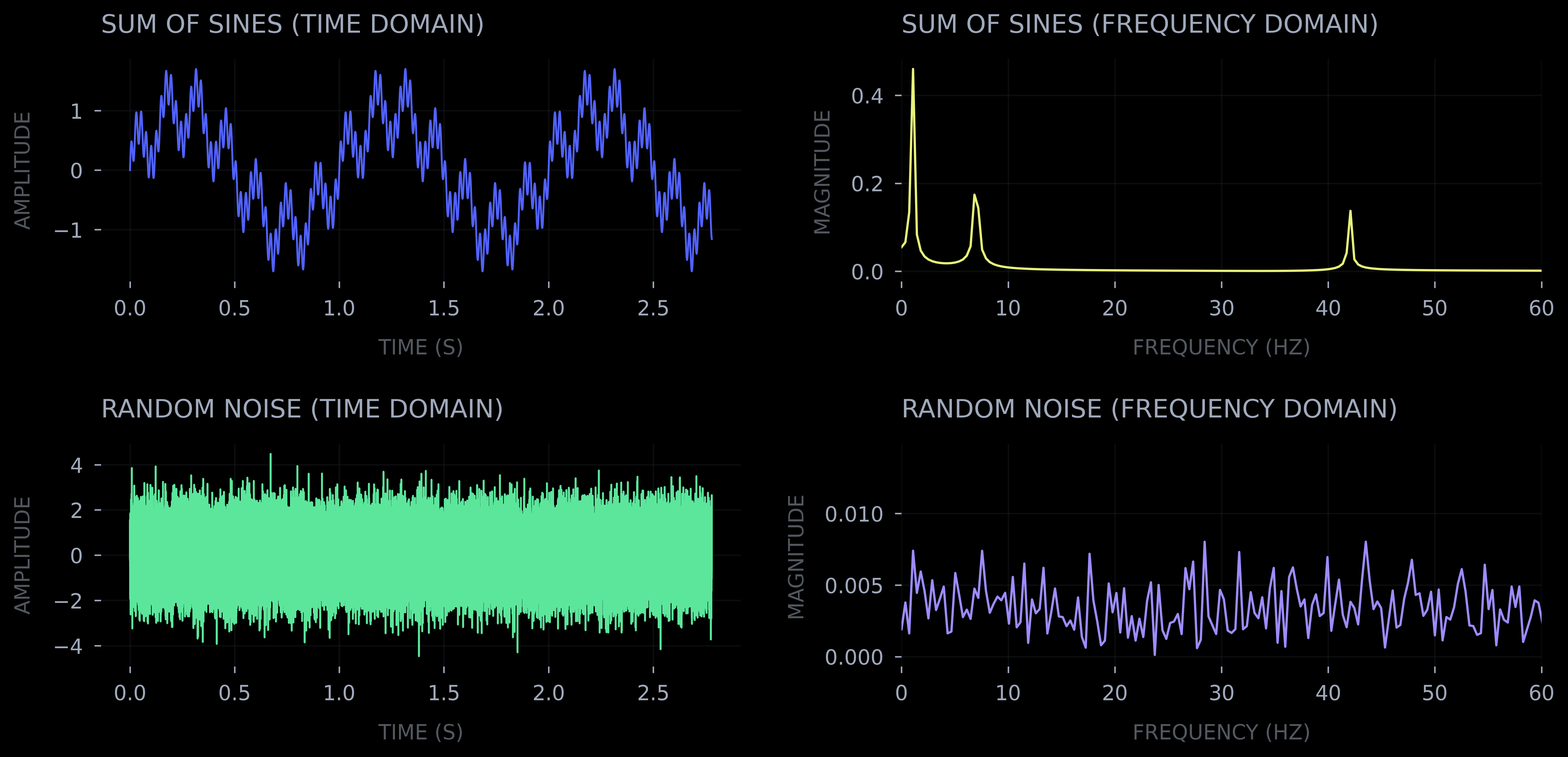
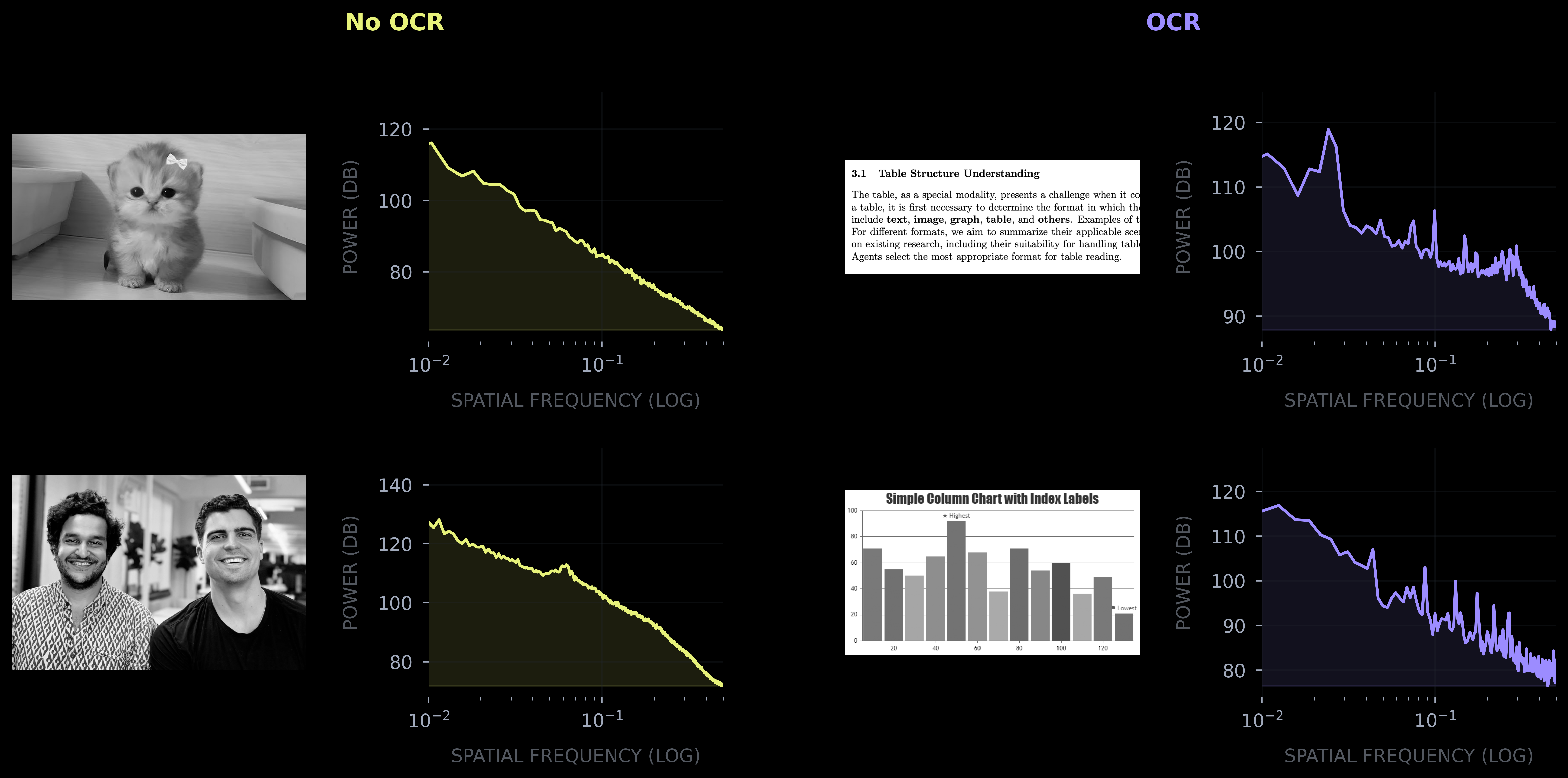
Text and natural images don't just look different, they are quantitatively different in ways that signal processing researchers characterized decades ago. Consider what text looks like structurally: horizontal lines repeating at consistent vertical intervals, vertical strokes at intervals set by character width and kerning. While natural images have structure too — edges, textures, objects — their distribution is much less regular. A photograph of a forest doesn't have the same pattern repeating every 12 pixels. The key is spatial regularity. Images of text exhibit multiple axes of periodicity, natural images do not.
The infamous Bitter Lesson, a term coined by reinforcement-learning godfather Richard Sutton, cemented the wisdom that methods leveraging more computation to learn patterns in large volumes of data consistently outperform approaches that build in human domain knowledge. Given enough data, compute, and parameters, a black box will discover patterns better than any human engineer.
This is broadly true, but for this narrow problem with well understood structure, inductive biases from signal processing for feature engineering can offset the need to throw compute at every challenge.
A Spectral Approach
The Fourier transform converts spatial data into the frequency domain. In one-dimensional signal processing modalities such as audio the spatial dimension is time. When dealing with images, the spatial dimensions are the X and Y coordinates.
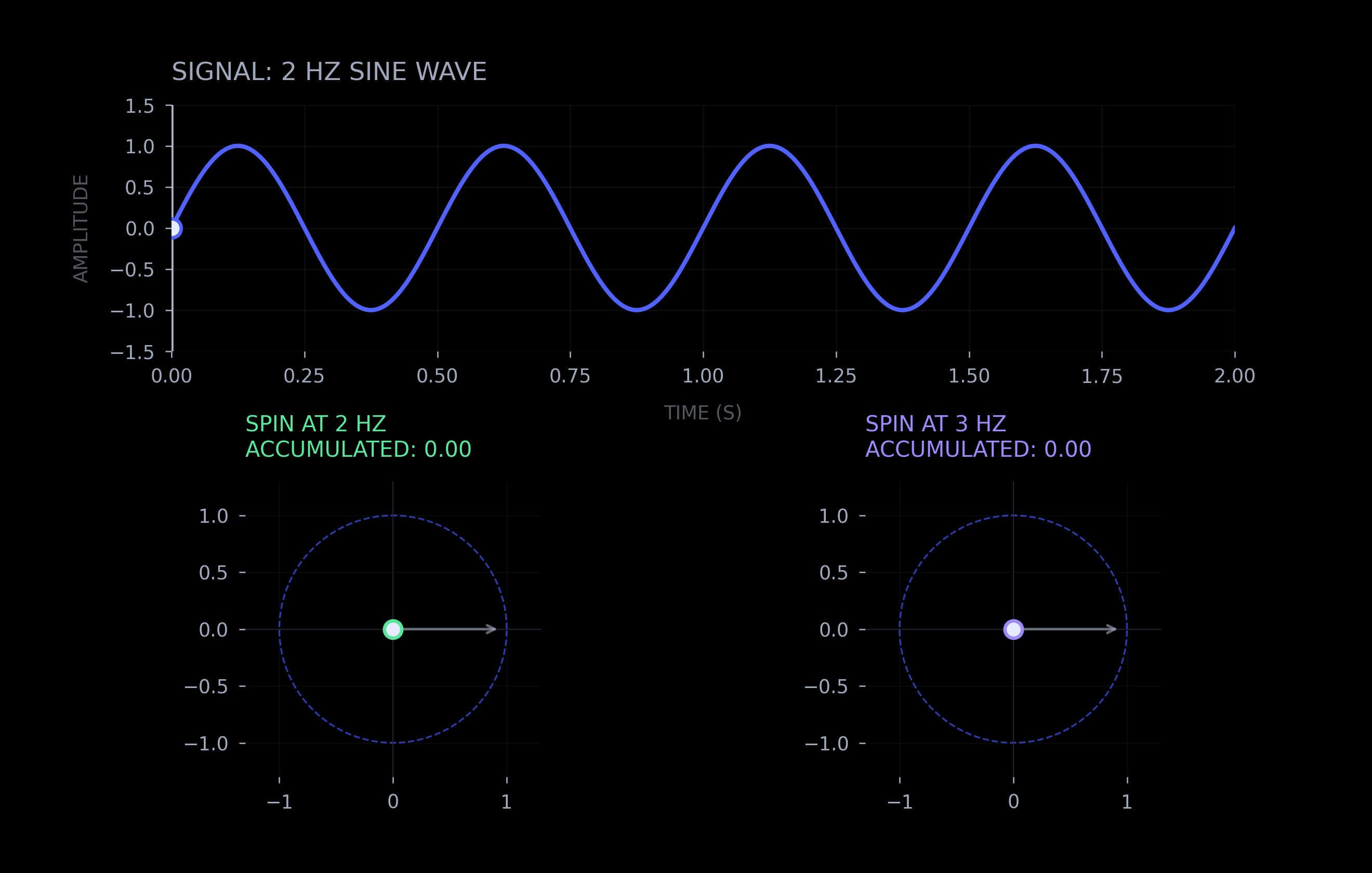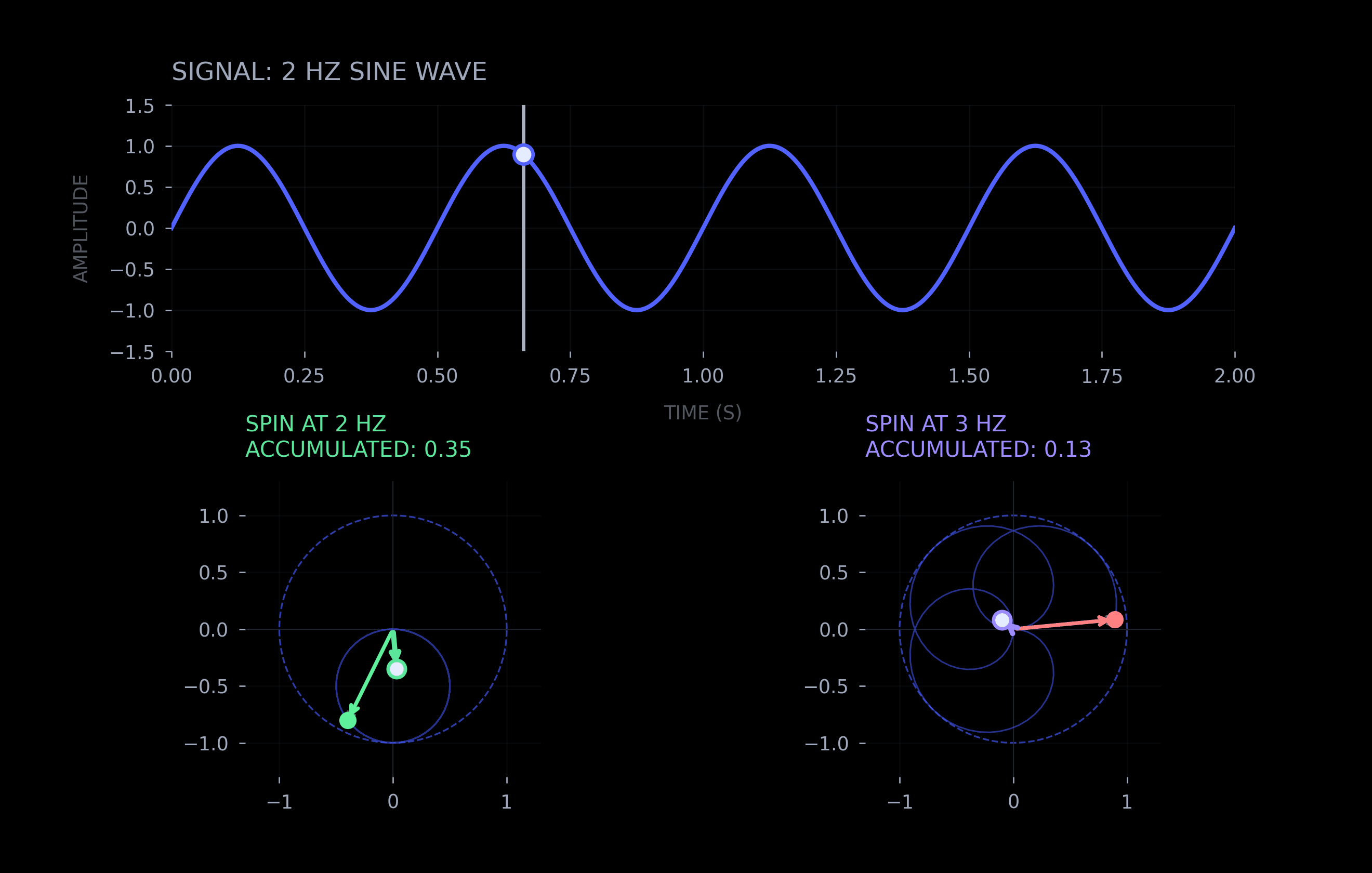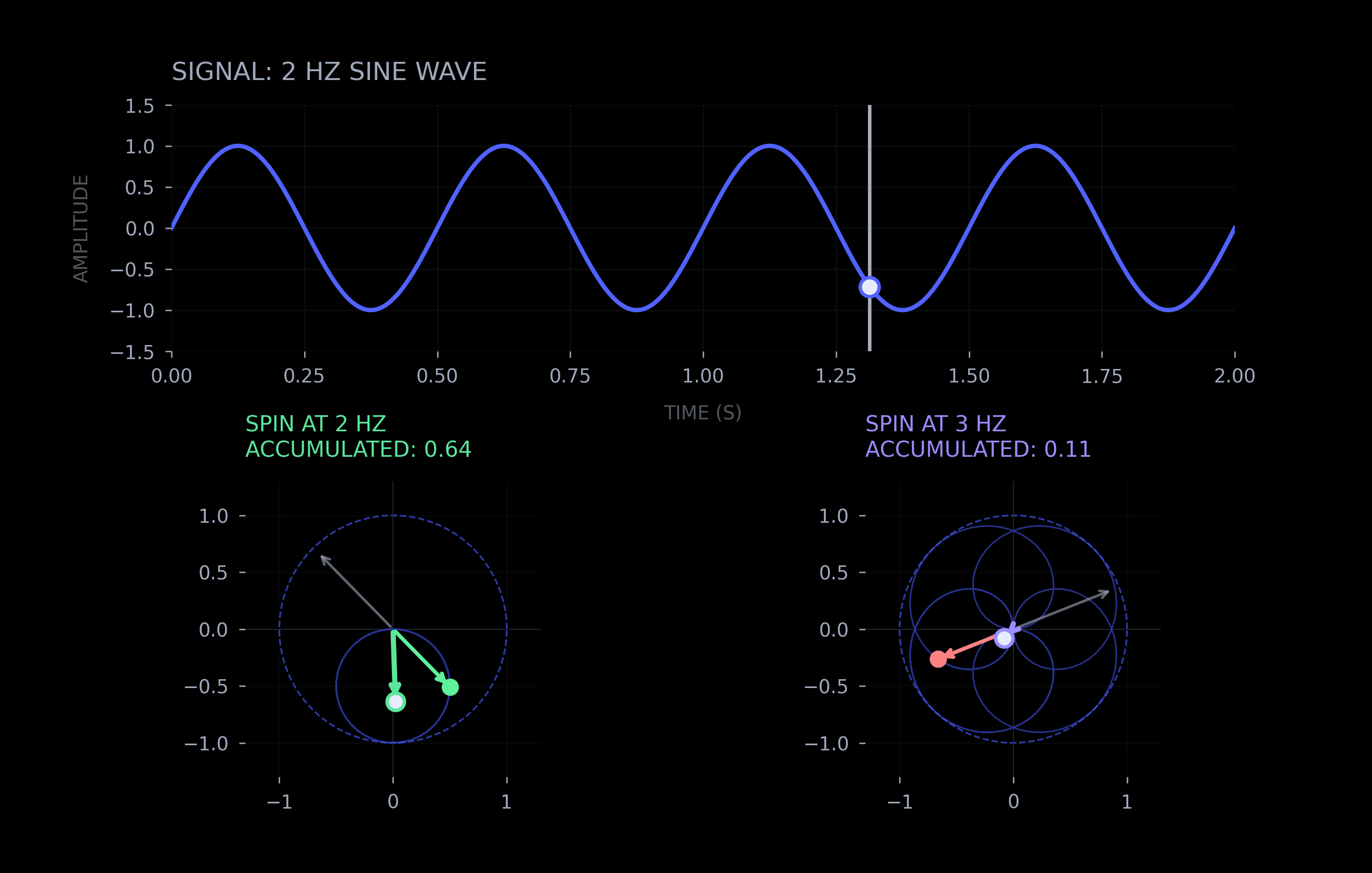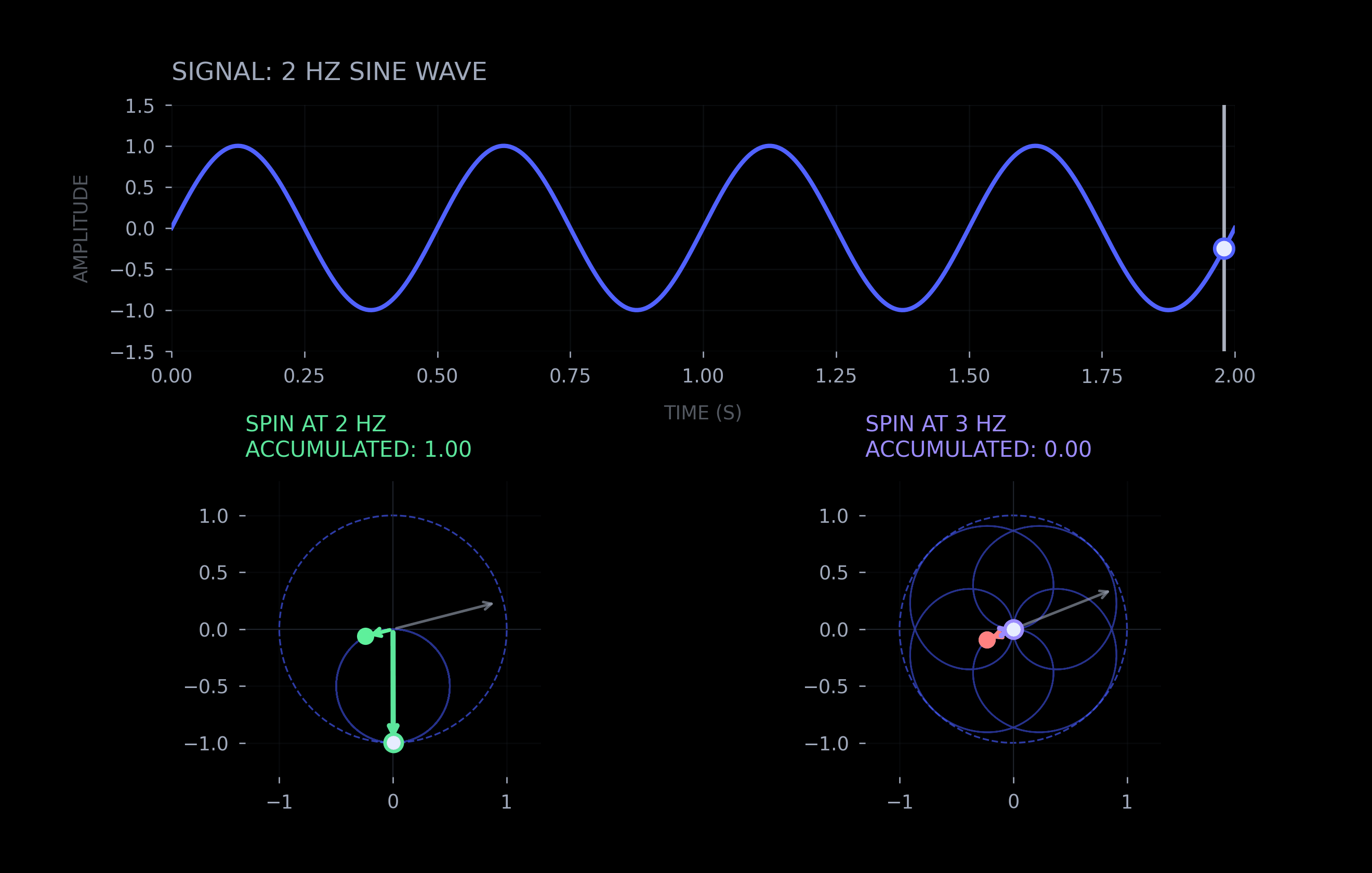
While math can appear intimidating at first, the core insight is intuitive. The Fourier transform spins the data (signal) in a circle and tracks the cumulative position of each spatial frequency (via integration). This allows measuring the strength of each frequency in the signal.
Euler's formula — e^(iθ) — traces a circle in the complex plane as θ changes. When a signal is multiplied by e^(-2πi·f·x), it is rotating through the data (x) at frequency (f). If the signal actually contains that frequency, the product accumulates; if not, it cancels out. Do this for every frequency and you get a spectrum — a measure of intensity of each frequency in the signal.
For a grayscale image I(x,y), we compute its 2D Fourier transform:
F(u,v) = ∫∫ I(x,y) e^(-2πi(ux+vy)) dx dy
The power spectrum |F(u,v)|² tells us how much energy exists at each spatial frequency. Text at any angle should produce the same signature, so to get a rotation-invariant representation we compute the radial power spectrum —averaging power across all orientations at each frequency:
P(r) = (1/2π) ∫ |F(r·cosθ, r·sinθ)|² dθ
Finally, we resample these spectra to 128 log-frequency bins. The result is drastic compression: any sized image becomes a 128-dimensional vector with features highly discriminative for text detection.
Applying the Fourier transform we compress the images’ dimensionality by 3-4 orders of magnitude, all while preserving the highly discriminative features for recognizing text. This entirely algorithmic approach is efficient, low latency, and able to run on CPUs.
Note: In practice, since images are discrete pixel grids, we compute the Discrete Fourier Transform via the FFT algorithm rather than evaluating these integrals directly.
Introducing FFTxt
FFTxt is a lean Multilayer Perceptron (MLP) that receives an image's 128-dim power spectrum as input. This compressed, lower dimensional input drastically reduces compute requirements for the actual model.
All in, the entire architecture clocks in at a lean 30,000 parameters. By utilizing 1D-convolutions for translational invariance to spectral peaks at different frequencies, FFTxt can represent different sized and spaced text. The model is augmented with several classic computer vision scalar features which are embedded with sinusoidal position encodings.
To train FFTxt, several thousand images were collected and labeled from public sources. We optimized with a vanilla binary cross entropy objective. Training runs converge in minutes on a laptop. The entire FFTxt inference pipeline runs end to end in less than a tenth of a second on arbitrarily sized images all on CPU.
Conclusion
The Bitter Lesson is that given infinite compute and data, learned representations will win. But we don't operate at infinity. We operate under latency budgets, memory constraints, cost ceilings, and capacity limits.
FFTxt demonstrates that when you deeply understand both the problem structure and your operational constraints, inductive insights can outperform brute force. By leveraging signal processing to recognize that text exhibits spatial periodicity that natural images don't, we built a 30K-parameter model that routes OCR with millisecond latency on CPUs. For Hebbia's financial analysis workflows, where millions of documents flow through our systems every minute, this approach is the only practical solution.


