
RAG Architecture: Explanation and Limitations
Retrieval-augmented generation, or RAG for short, has become a staple of AI-driven workflows in knowledge work. RAG architecture is designed to pull data from relevant sources and relay it to large language models (LLMs), enabling them to provide more accurate, context-informed responses.
For many professionals, RAG has proven sufficient. RAG powers chatbots, enables enterprise search, helps with content generation, and more. However, in the finance industry, many of RAG architecture’s most prevalent limitations are exposed quickly. Frequent inaccuracies, incorrect analyses, and unexplainable reasoning become commonplace, leading to reduced trust, wasted time, and damaged credibility.
In this article, we’ll break down what retrieval augmented generation is, how it works, and the limitations that make it a less-than-ideal solution for finance professionals.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation is a framework that improves the accuracy of LLMs by pulling data from external, up-to-date sources (beyond the static data the model was trained on) before generating a response. RAG architecture effectively enables LLMs to incorporate real-time, domain-specific information into their outputs, thereby reducing the risk of hallucinations and enabling more timely, relevant responses.
RAG in AI provides improved accuracy compared to standalone LLMs, making it a popular implementation in business across various industries. It powers everything from customer service chatbots to enterprise search platforms. With that said, RAG architecture still carries significant limitations, particularly with workflows that demand precision at scale, multi-step reasoning, and auditability, making it a subpar solution for the finance industry.
How Does RAG Work?
RAG works by retrieving information from outside an LLM’s training data and using it to modify user prompts, yielding more accurate outputs. It can be broken down into two simple stages:
- Information retrieval: The system identifies and pulls data it determines to be timely and relevant to the user’s query. This could include both internal databases and documents, as well as external sources such as websites or connected repositories.
- Output generation: The RAG LLM combines the retrieved data with the user’s original query, allowing it to look beyond its training data to provide a more context-informed answer.
RAG Architecture: A Step-by-Step Breakdown
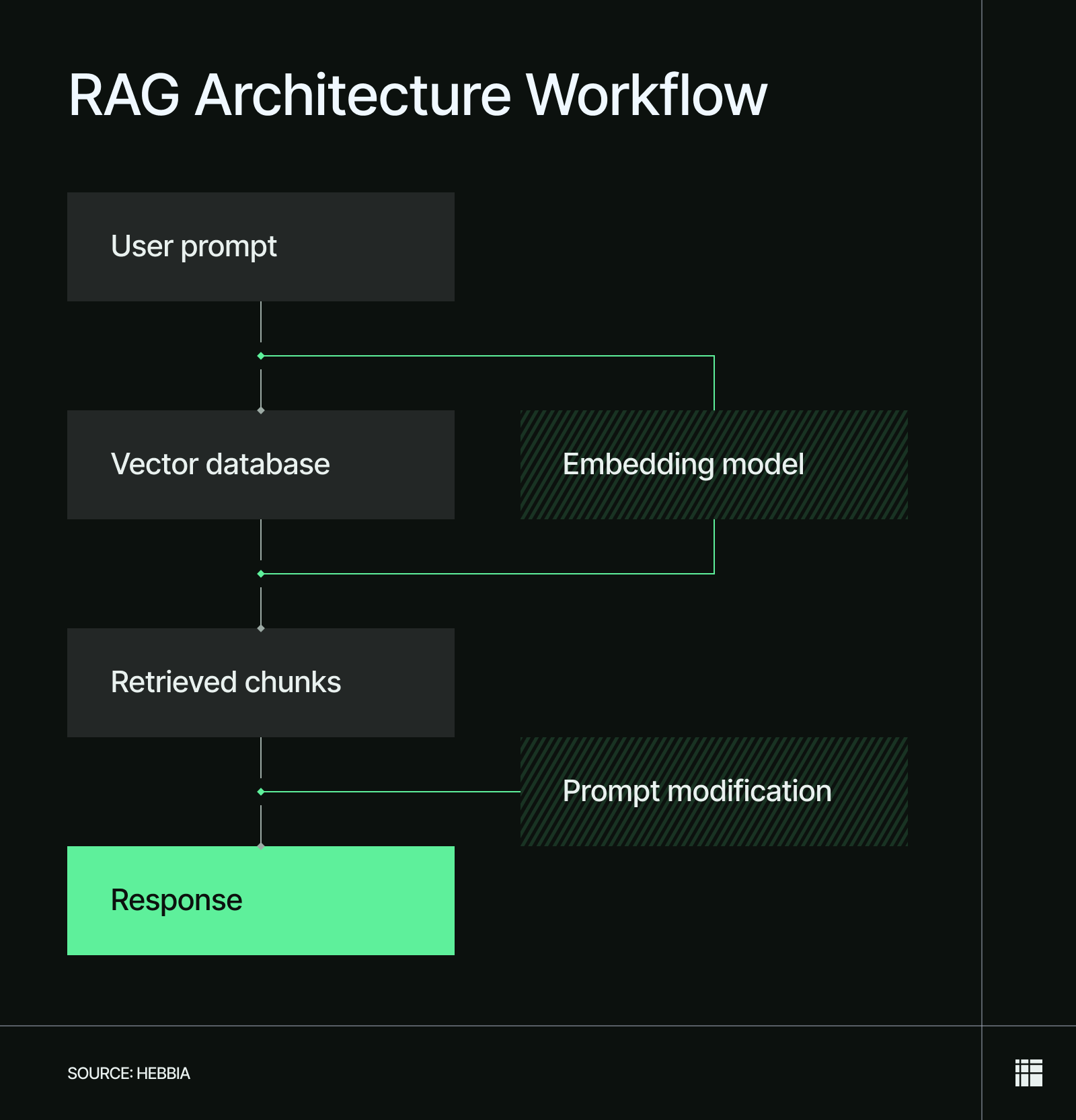
RAG architecture processes and vectorizes user queries, retrieves relevant information from a vector database, and then implements it into the user query to help the LLM generate a better answer. Below is a step-by-step breakdown of the flow depicted in a typical RAG architecture diagram, explaining how the process works.
- User query processing: The user submits a natural-language prompt to an LLM, typically a question or request. The RAG system then processes the query (e.g., removing noise, rewriting, or expanding it) to improve retrieval quality.
- Query embedding: The processed query gets passed to an embedding model, which converts the text into a vector that encodes its semantic meaning.
- Information retrieval: The RAG system searches a vector database, comparing its contents with the vectorized query to identify the most similar elements (usually in the form of document chunks).
- Prompt refinement: The RAG engine refines the user’s prompt into a stronger, more data-rich version by inserting the most relevant chunks and then forwards it to the LLM.
- Output generation and delivery: The LLM processes the original query and refined prompt provided by the RAG engine to generate a more accurate response than it could on its own. It then forwards the response to the user.
For users, interacting with a RAG LLM is effectively the same as interacting with any other type of LLM. The only difference is that the responses they receive are generally more accurate.
For example, a finance professional executing an AI due diligence workflow might type out this query: Summarize [X Company]'s liquidity position and any mentioned constraints on their revolving credit facility. A RAG-enabled LLM can search their firm’s internal database, referencing things like recent financial statements, credit agreements, and internal risk reports to deliver a more precise summary than a standard LLM.
RAG Architecture Limitations: Why It’s Not Suited for Finance
While RAG is measurably more accurate than a standard LLM, it still doesn’t provide the level of accuracy, auditability, and versatility that finance professionals need.
AI solutions for finance need to answer highly complex queries, demonstrate multi-step reasoning, and preserve context at scale. This is precisely where RAG falls short: our data indicates that it fails on over 84% of user queries in finance.
1. Persistent Inaccuracies and Hallucinations
At its core, RAG simply adds a retrieval layer on top of LLMs. The added context can help, but it doesn’t stop an LLM from making false inferences or yielding factually incorrect data to fill a gap. RAG systems can also fail to retrieve the most relevant or recent information, especially if their retrieval pipeline is flawed.
Document chunking can compound the issue. To store and search long documents efficiently, RAG systems break them into smaller pieces, which can sever context. This creates a structural issue when working with large documents that require scanning multiple sections to ascertain meaning, such as credit agreements, regulatory filings, or historical investment committee memos.
If left unchecked, these problems can lead to fundamental inaccuracies, flawed analyses, and severe damage to a firm’s credibility.
2. Improper Source Attribution
Many RAG implementations don’t offer source attribution for their outputs. If they do, it’s often limited in a way that makes it impractical for finance workflows. For instance, a RAG system may:
- Fail to provide citation links, only naming the documents that the information was pulled from. This forces professionals to manually find the specific document.
- Only link to the larger document, website, or spreadsheet where the information was pulled from, rather than the exact location of the information. This makes people do a Ctrl+F search to find and verify each citation’s validity.
- Not provide in-line citations, which can impede auditability, make it harder to discern facts from analysis, and significantly reduce trustworthiness.
Our study of AI trends in financial services revealed that industry professionals demand accountability for AI outputs. Forty-nine percent (49%) need quick verification, 37% want transparency, and 34% require clear citations. For each of these, professionals need clickable, in-line citations that link to the specific passage, source, or cell where the information was pulled. Anything less can pose unacceptable risks in an industry with a low tolerance for errors.
3. Limited Context Window
While RAG powers many of the best AI document analysis tools, it's held back by a limited context window. Document chunking helps extract relevant information but risks presenting data without context, especially when applied to long, structurally complex documents like those finance professionals often work with.
For a 10-page PDF, RAG will be perfectly sufficient in most cases. But consider a standard Form 10-K. A company’s top-level "Adjusted EBITDA" might be highlighted in the Management’s Discussion and Analysis (MD&A) on page 30, but the critical footnote detailing the massive, one-time restructuring charges excluded from that calculation is buried in the financial appendices on page 115.
Because RAG chunks documents into isolated pieces, it might retrieve the flattering top-line metric while entirely missing the context of the underlying liabilities. This is a factually correct, but strategically meaningless output, and can lead to inaccurate conclusions if not identified.
4. Limited Reasoning Capacity
RAG engines struggle with queries that require complex reasoning, conditional logic, and cross-document analysis. Notoriously, RAG systems also commonly fail to understand structured (tables, charts, spreadsheets, etc.), visualized, or fragmented data. As a result, finance professionals who rely on RAG for rigorous analysis often don’t get their questions answered or receive nonsensical answers.
What’s worse, many RAG systems lack transparency, meaning no audit logs, no visible reasoning for changes, and no mechanism for a professional to trace how a conclusion was reached. For workflows that require defensible analysis, whether for internal review, client delivery, or regulatory compliance, that opacity is a fundamental limitation that enhanced prompt engineering alone can’t solve.
Overcome the Limitations of RAG with Hebbia’s Iterative Source Decomposition
RAG architecture is built on a foundation of information retrieval and output generation, enabling LLMs to produce better, more context-informed responses to user queries. That said, RAG has multiple severe limitations that become immediately apparent when applied to finance workflows.
With over five years of focused development for the finance industry, Hebbia created iterative source decomposition (ISD) technology, which overcomes all of RAG’s major limitations and allows finance professionals to tap into automation at scale.
ISD represents a direct upgrade to RAG, delivering the most complete and trustworthy outputs among AI platforms in finance today. With each output, you get:
- Better context and structure preservation across complex documents compared to traditional RAG
- Clickable in-line citations that link to the precise passage, cell, or clause that each data point was pulled from
- Immutable audit logs that show reasoning and logic, enabling defensible analysis at scale
Book a demo to see why leading firms across the industry, from investment banks to credit and asset management firms, choose Hebbia to automate their workflows.


